如何在上億筆使用者中檢查名稱是否存在
前言
在APP註冊時,有時會被提示使用者名稱已存在,這個功能該如何實現?
比較直覺的方法是直接在資料庫中進行檢索,但資料量到達億級別時,這種方法肯定不可行,
此篇會利用Redis內建布隆過濾器(Bloom Filter)資料結構實現
使用資料庫查詢
1 | SELECT COUNT(*) FROM users WHERE username = ? |
此方法會有以下缺點
- 在資料量大的情況,頻繁進行資料庫查詢,會造成效能下降、延遲,且查詢速度緩慢
- 資料庫負載高,每個查詢都會消耗資源,CPU和I/O
資料存放於快取
快取會佔用記憶體空間,直接將上億筆資料放入快取並非好的辦法
布隆過濾器(Bloom Filter)
在此以查詢使用者名稱為例
過濾器核心思想如下
- Bit Array :一條大型元陣列,每個位置初始值為零,每個位置只會存放0或1,用來表示該元素(使用者名稱)是否存在。
- Hash Functions:過濾器使用多個哈希函數,每個函數可以將輸入的使用者名稱映射到bit array的一個或多個位置。

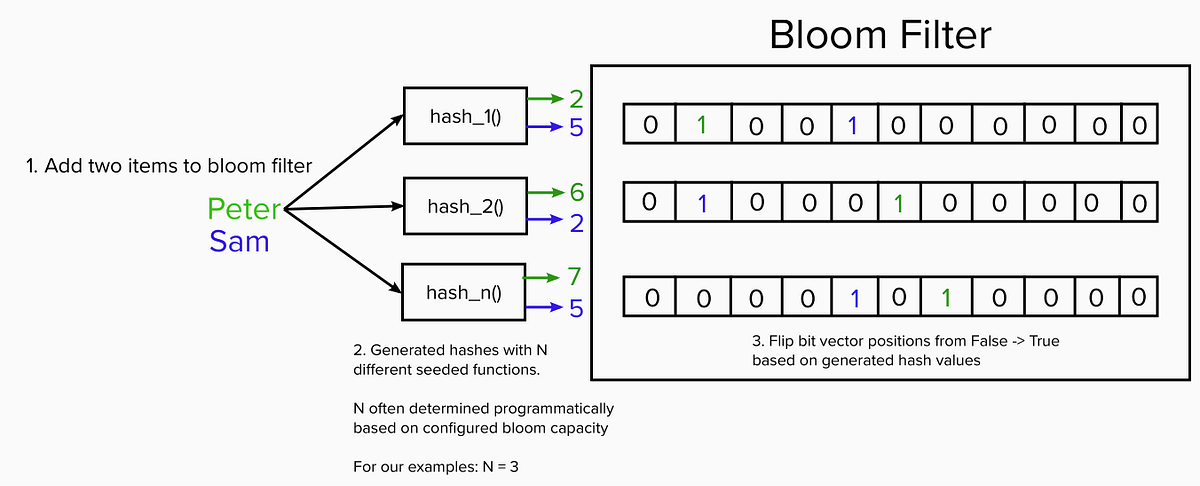
使用上有兩種方法
- 新增元素
- 查詢元素
假設資料庫中有一億筆使用者,要先將所有使用者逐一添加至布隆過濾器,透過Hash Functions映射至bit array,當欲查詢使用者是否存在,會將使用者名稱透過Hash Functions映射至bit array相應位置,若該位置為1,代表存在,若為0代表不存在。
程式範例
1 | const Redis = require('ioredis'); |
布隆過濾器優缺點
優點
- 節省內存空間,不需直接將上億筆實際資料存放在快取,而是只存放透過hash functions轉換的哈希值。
- 高效率查詢,不用搜索整個資料庫,時間複雜度僅為O(1)
缺點
- 存在誤判率,有可能會誤判該元素已存在,但絕對不會誤判該元素不存在!因此不用擔心重名的問題
- 不能刪除元素,從集合中刪除元素會影響哈希值,增加誤判率
加入過濾器的耗時問題
- 將十億筆資料加入布隆過濾器的確可能會相當耗時,這取決於您的硬體資源、布隆過濾器的實現方式以及數據的加載速度。為了優化這一過程,可以考慮以下幾點:
- 批量處理:在加載數據到布隆過濾器時,可以採用批量處理的方式,以減少單次插入的開銷。
- 後台處理:可以在伺服器啟動後,利用後台任務進行數據的加載,以避免阻塞主要的服務流程。
- 分段加載:如果可能,可以將布隆過濾器的建立和更新過程分段進行,避免一次性處理所有數據。
資料庫有新增使用者的處理方式
- 對於資料庫中新增的使用者,確實需要將這些新使用者加入到布隆過濾器中,以保持布隆過濾器數據的最新性。這個過程可以通過以下方式進行:
- 即時更新:每當資料庫新增一個使用者時,同時將這個使用者名稱加入到布隆過濾器中。這要求系統能夠處理這些即時更新的操作。
- 定期更新:根據系統的實際需求和容錯率,可以選擇定期將新增的使用者名稱批量加入到布隆過濾器中。
欲刪除使用者的處理方式
布隆過濾器不支持直接從集合中刪除使用者
1. 使用可計數的布隆過濾器(Counting Bloom Filter)
可計數的布隆過濾器是布隆過濾器的一個變體,它不僅記錄某位是否被映射,而且記錄映射到該位的元素數量。這樣,當您需要“刪除”一個元素時,只需將該元素對應位上的計數減一。如果計數降至零,則相當於該位未被任何元素映射。但這種方法需要更多的空間來存儲計數信息。
2. 重建布隆過濾器
當資料庫中刪除了一些元素後,您可以通過重新從資料庫中加載剩餘元素來重建布隆過濾器。雖然這個過程可能比較耗時,但它能夠確保布隆過濾器中的信息與資料庫保持一致。這種方法適用於元素刪除操作不頻繁的場景。
3. 使用其他數據結構輔助
另一種策略是結合使用布隆過濾器和其他數據結構,例如哈希表。當布隆過濾器判斷一個元素可能存在時,可以進一步查詢哈希表來確定該元素是否真的存在。當元素被刪除時,只需要從哈希表中刪除該元素。這樣可以保持快速查詢的同時,也能夠處理元素的刪除操作。